Google ignoriert die Robots.txt von Shopware
09.06.2020 von Nils Abegg
In manchen Fällen ignoriert der Google Bot die Anweisungen der Robots.txt von Shopware Installationen mit einer Version unter 5.6.2. Wie es dazu kommt und vor allem, wie du das behebst, lernst du in diesem Artikel.
Während eines Kundenprojekts ist mir aufgefallen, dass bei diesem Kunden viele Warnungen in der Google Search Console auftauchen, die dort eigentlich nicht sein sollten, da sie durch die Robots.txt ausgeschlossen werden. Nachdem ich alle Faktoren auf der Shop-Seite geprüft hatte, war ich mir sicher, dass es nicht an der Robots.txt liegen kann und Google diese wohl einfach ignoriert. Eine kurze Google-Suche nach "widgets/index/refreshstatistic" brachte über 3.000 Ergebnisse hervor. Den Sucbegriff hatte ich aus den Einträgen der Google Search Console des Kundens abgeleitet.
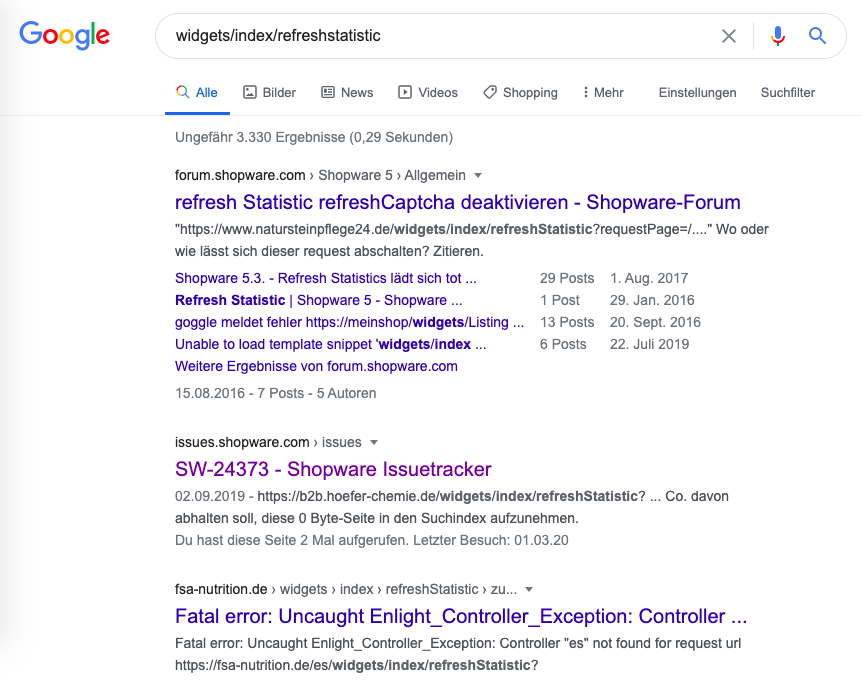
Mein Kunde hatte also auch nicht den einzigen betroffenen Shop und das Problem war bei Shopware auch schon bekannt.
Was ist da nun los?
Im Eintrag des Shopware-Issue-Trackers hat der Author Christian Berlin erwähnt, dass Google die Einträge der Robots.txt in manchen Fällen ignoriert, wenn die URLs Google auf einem anderen Wege bekannt gemacht werden. Da mir das unbekannt war und der Author keine Quelle angegebn hatte, habe ich selbst kurz recherchiert und eine Pressemitteilung von Google gefunden, die besagt, dass Google ab September 2019 unter anderem die Disallow-Regel in der Robots.txt nicht mehr unterstützen wird.
Die von Google vorgeschlagene Alternative die Indexierung von Seiten per HTTP-Header zu blockieren, wird von Shopware grundsätzlich unterstützt, nur leider fehlerhaft. Google erwartet den HTTP-Header x-robots-tag, Shopware sendet aber nur x-robots, was dafür sorgt, dass Google diese Anweisung nicht korrekt verarbeitet und somit ignoriert.
Wie fixen wir das?
Da es in der IT meistens viele Wege ans Ziel gibt, gibt es auch hier 3 Wege zur Auswahl, die ich einmal kurz vorstellen möchte:
- Ein Update auf Shopware 5.6.2+
Shopware hat das Problem im September 2019 mit der Version 5.6.2 behoben. Für viele Shops ist das sicher der steinigste Weg, aber natürlich auch der, der am Ende am meisten belohnt. - Hotfix selber vornehmen
Man kann natürlich einfach an der Stelle im Shopware Core Code, wo Shopware den HTTP-Header setzt "x-robots" zu "x-robots-tag" ändern. Dies sollte in diesem Fall auch nicht zu anderen Komplikationen führen, aber ausschließen kann man es auch nicht zu 100%. Dieser Weg ist sicher der bequemste, aber ich würde definitiv davon abraten, Änderungen an den Core-Dateien von Shopware vorzunehmen. Deshalb gibt's hier auch keine detailierte Anleitung dazu. - HTTP-Header per Webserver setzen
Dieser Weg benötigt leider sehr viel Handarbeit, aber lässt sich dafür meistens problemlos in eigentlich jedem erdenklichen Shop-Setup umsetzen. Hierfür müssen erst alle betroffenen Seiten der eigenen Shop-Domain identifiziert werden, um diesen Seiten dann im Webserver automatisch einen Header hinzufügen zu lassen, der dafür sorgt, dass diese Seite nicht mehr von Google indexiert werden.
In den nächsten Schritten werde ich darauf eingehen, wie man die HTTP-Header per Webserver setzen kann, um Google dazu zu zwingen, die gewünschten Seiten nicht zu indexieren, bzw. zu crawlen.
Betroffene Seiten identifizieren
Im ersten Schritt müssen die betroffenen Seiten im eigenen Shop erst einmal identifiziert werden. Hierzu braucht man den Inhalt seiner eigenen Robots.txt. Ich nehme hier als Beispiel die Datei die mit Shopware 5.5 kam.
User-agent: *
Disallow: /compare
Disallow: /checkout
Disallow: /register
Disallow: /account
Disallow: /address
Disallow: /note
Disallow: /widgets
Disallow: /listing
Disallow: /ticketWie man sieht ist der Aufruf den ich in meiner intialen Google-Suche genutzt hatte eigentlich gesperrt. Um zu testen, ob das bei Dir auch so ist, musst Du "/widgets site:DEINEDOMAIN.DE" bei Google eingeben und dir die Ergebnisse anschauen. Beachte, dass du vorher DEINEDOMAIN:DE mit deiner Shop-URL ersetzt. Im Idealfall bekommst du kein Ergebnis und wenn du Ergebnisse hast, musst du diese überprüfen, ob diese gewollte Ergebnisse sind, oder nicht. Wenn sich daraus Handlungsbedarf ergibt, sollten unbedingt die anderen Einträge der Robots.txt nach gleichem Schema in Google gesucht werden, um das komplette Ausmaß einschätzen zu können.
Jetzt müssen wir für jeden Eintrag der Robots.txt, der zu ungewollten Ergebnissen bei Google führt, dem Webserver mitteilen, dass er bei diesen Aufrufen einen korrekten HTTP-Header setzt, der die Indexierung verhindert.
HTTP-Header mit Apache setzen
Da sich die Möglichkeiten hier von Hoster zu Hoster bzw. Setup unterscheiden, möchte ich hier nur exemplarisch zeigen, wie man es bei Apache mit einer Vhost-Konfiguration lösen könnte. Dazu muss einfach folgender Konfigurationsblock in die Vhost-Konfiguration für den Shop kopiert werden und alle Einträge mit "/widgets/" in der URL sollten bald wieder aus Google verschwunden sein. Wenn mehrere Controller betroffen sind, macht es auch Sinn, die LocationMatch Direktive einzusetzen. Aber dein Hoster, bzw. Administrator weiß bestimmt besser, wie er das in deinem Shop umsetzen kann.
<Location */widgets/*>
Header set X-Robots-Tag "noindex, nofollow"
</Location>HTTP-Header mit nginx setzen
Bei nginx gibt es nicht so zahlreiche Möglichkeiten, um an das Ziel zu kommen, aber da sich auch hier die Wege der Hoster zu stark unterscheiden, möchte ich nur die nginx-Direktive vorstellen, mit der man das Problem lösen kann. Auch hier sollten nach einem Neustart von nginx die unerwünschten Ergebnisse für alle URLs mit "/widgets/" nach spätestens 30 Tagen aus Google verschwunden sein.
location /widgets/ {
add_header X-Robots-Tag "noindex, nofollow";
}Fazit
Du solltest erst einmal überprüfen, ob du betroffen bist und in deinem Shop Handlungsbedarf besteht. Wenn Handlungsbedarf besteht und ein Update auf Shopware Version 5.6.2 keine Option darstellt, solltest du dich mit deinem Hoster oder Administrator zusammensetzen und die korrekten HTTP-Header per Webserver ausspielen. Nach 14-30 Tagen sollten die fälschlicherweise indizierten Seiten wieder aus Google verschwunden sein. Falls man ein Crawling der betroffenen Seiten per Google Search Console manuell anfordert, kann es auch schneller gehen. Falls du Fragen oder Feedback zu diesem Artikel hast, kannst du dich gerne per E-Mail bei mir melden. Ich werde den Artikel dann ergänzen.
Quellen
-
Eintrag im Shopware Issue-Tracker
https://issues.shopware.com/issues/SW-24373 -
Ankündigung von Google bezüglich der Robots.txt
https://webmasters.googleblog.com/2019/07/a-note-on-unsupported-rules-in-robotstxt.html -
Dokumentation der Spezifikationen für X-Robots-Tag
https://developers.google.com/search/reference/robots_meta_tag?hl=de -
Apache Dokumentation für Location Direktive
https://httpd.apache.org/docs/2.4/de/mod/core.html#location -
Apache Dokumentation für Header
https://httpd.apache.org/docs/2.4/mod/mod_headers.html -
nginx Dokumentation für Location Direktive
http://nginx.org/en/docs/http/ngx_http_core_module.html#location -
nginx Dokumentation für Header
http://nginx.org/en/docs/http/ngx_http_headers_module.html